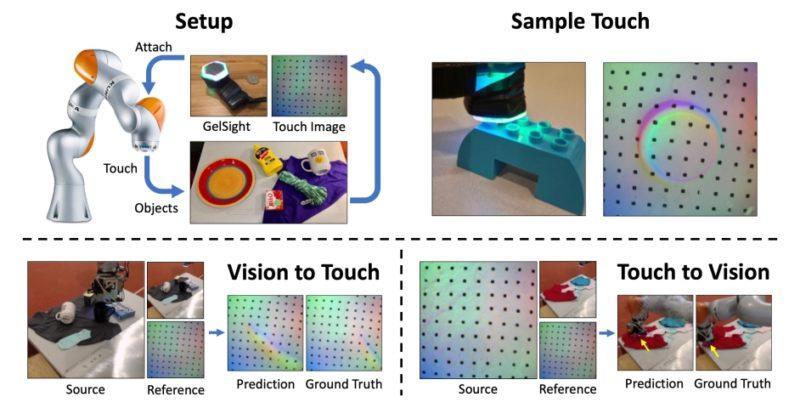
Роботы, которые смогут ориентироваться в пространстве на ощупь, появятся в недалёком будущем, утверждают исследователи из Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (MIT). В недавно опубликованной ими научной работе, которая будет представлена на этой неделе на Конференции по компьютерному зрению и распознаванию образов в Лонг-Бич, Калифорния, они описывают систему на базе искусственного интеллекта (ИИ), способную воссоздавать визуальный образ объекта по тактильным ощущениям и предсказать тактильные ощущения от прикосновения к нему на основе изображения.
Учёные из MIT научили ИИ использовать тактильные ощущения. Пока что на ограниченной выборке, но ИИ уже может понять к чему и где он прикасается, а также предсказать ощущения от прикосновения к объекту на основе одного лишь изображения
«Используя визуальное изображение, наша модель может представить возможные ощущения от прикосновения к плоской поверхности или к острому краю», — говорит аспирант Лаборатории искусственного интеллекта MIT и ведущий автор работы Юнчжу Ли (Yunzhu Li), который провёл исследования вместе с профессорами MIT Руссом Тедрейком (Russ Tedrake) и Антонио Торралба (Antonio Torralba), а также постдокторантом Джун-Ян Чжу (Jun-Yan Zhu). «Просто касаясь объектов без использования зрения, наша ИИ-модель может предсказать взаимодействие с окружающей средой исключительно по тактильным ощущениям. Объединение этих двух чувств может расширить возможности роботов и уменьшить объем данных, которые требуются для выполнения задач, связанных с манипулированием и захватом объектов».
.gif)
ИИ предсказывает тактильные ощущения на базе визуальной информации (зелёный квадрат — данные с тактильного сенсора, красный — предсказание ИИ)
Для генерации изображений на основе тактильных данных команда исследователей использовала GAN (англ. Generative adversarial network — генеративно-состязательная сеть) — двухчастную нейронную сеть, состоящую из генератора, который создаёт искусственную выборку, и дискриминатора, которые пытаются различить сгенерированные и реальные образцы. Обучалась модель на специальной базе данных, которую исследователи назвали «VisGel», представляющую собой совокупность из более чем 3 миллионов пар визуальных и тактильных изображений и включающую в себя 12 000 видеоклипов почти 200 объектов (таких как инструменты, ткани и товары для дома), которые ученые самостоятельно оцифровали при помощи простой веб-камеры и тактильного датчика GelSight, разработанного другой группой исследователей в MIT.
Используя тактильные данные, модель научилась ориентироваться относительно места прикосновения к объекту. Например, используя эталонную выборку данных по обуви и снятые с тактильного датчика данные, путём сравнения определить, к какой части обуви и с какой силой в данный момент прикасается манипулятор Kuka. Эталонные изображения помогли системе правильно декодировать информацию об объектах и окружающей среде, позволяя дальше ИИ самосовершенствоваться самостоятельно.

На базе тактильной информации ИИ определяет, какого объекта коснулся манипулятор и в каком месте (зелёный квадрат — считывание информации, красный — поиск места предыдущего касания при помощи ИИ)
Исследователи отмечают, что текущая модель имеет примеры взаимодействий только в контролируемой среде и пока ещё малопригодна для практического применения, и что некоторые параметры, например, такие как мягкость объекта, системе определить пока ещё сложно. Тем не менее, они уверены, что их подход заложит основу для будущей интеграции человека с роботом в производственных условиях, особенно в тех ситуациях, когда визуальных данных просто недостаточно, например, когда свет по каким-то причинам отсутствует, и человеку приходится манипулировать с объектами вслепую.
«Это первая технология, которая может достоверно транслировать визуальные и сенсорные сигналы друг в друга», — говорит Эндрю Оуэнс (Andrew Owens), научный сотрудник Калифорнийского университета в Беркли. «Подобные методы потенциально могут быть очень полезны для робототехники, когда вам нужно ответить на вопросы типа „Этот объект твёрдый или мягкий?“ или „Если я подниму эту кружку за ручку, насколько надёжен мой захват?“ — это очень сложная задача, так как сигналы очень разные, и эта модель (созданная исследователями из MIT) продемонстрировала большие возможности».